TL;DR
Project concerned with Herbaria OCR techniques to extract all text from a given image to display the specimen information in the desired DarwinCore format for accomplishing the larger goal of preservation of early 19th century species through digitization. Machine learning pipeline using AI Vision models as well as text processing through GPT-4 along with evaluation of the training data was done successfully, culminating in deployment and a poster presentation to the BU Spark! committee. Here is a high-level visualization of the pipeline:
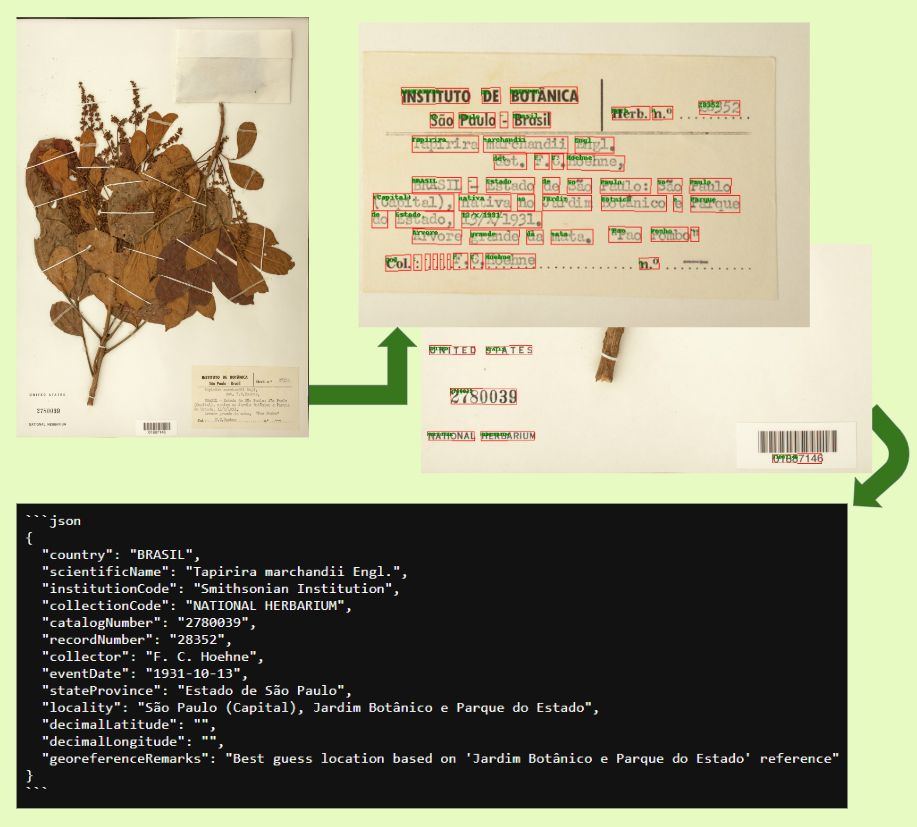
Overview
The changing climate increases stressors that weaken plant resilience, disrupting forest structure and ecosystem services. Rising temperatures lead to more frequent droughts, wildfires, and invasive pest outbreaks, leading to the loss of plant species. That has numerous detrimental effects, including lowered productivity, the spread of invasive plants, vulnerability to pests, altered ecosystem structure, etc. The project aims to aid climate scientists in capturing patterns in plant life concerning changing climate. The herbarium specimens are pressed plant samples stored on paper. The specimen labels are handwritten and date back to the early 1900s. The labels contain the curator’s name, their institution, the species and genus, and the date the specimen was collected. Since the labels are handwritten, they are not readily accessible from an analytical standpoint. The data, at this time, cannot be analyzed to study the impact of climate on plant life. The digitized samples are an invaluable source of information for climate change scientists, and are providing key insights into biodiversity change over the last century. Digitized specimens will facilitate easier dissemination of information and allow more people access to data. The project, if successful, would enable users from various domains in environmental science to further studies pertaining to climate change and its effects on flora and even fauna.
The Project
The objective of the project was to develop a machine learning solution for automating the extraction and digitization of critical information from handwritten and typed text labels on historical herbarium specimens, dating back to the early 1900s. These labels include: location, date collected, collector name etc. The goal is to be able to automatically upload these labels to a database. We will be contributing our work to the existing Github repo. We extended the project to include support for recognizing Chinese and Cyrilic characters as well.
We created a pipeline that made use of the Azure AI vision API to extract all the characters from the image, pass it through the GPT-4 API to format the text correctly and appropriately according to the Darwin Core standard for biodiversity specimen information. The project concluded with us successfully extracting the Taxon, Collector and Geography labels from the training data to satisfactory accuracy results. The evaluation methods for this project were extremely thorough and we made sure to
Project Deployment
We successfully presented our work at Boston University’s Spark! Demo Day of Fall 2023 to the inquisitve panel of members in the form of a poster. Here’s a picture of the team!

The work is also publicly accessible through an application hosted on HuggingFace Spaces through Gradio. It is as simple as uploading your Herbaria specimen image and waiting for the pipeline to extract all the text and display it in an easily accessible and logical JSON format. Here is a recording of the app in action!
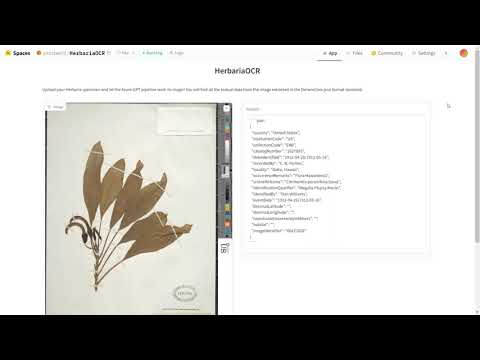
Note : This app is built upon our Herbaria OCR pipeline that relies on API keys from Microsoft Azure Vision and GPT-4. These access keys were provided by the Boston University Spark! Department and we are very much grateful to them for these resources. Therefore, if the API keys do not seem to work due to access issues or expiration of the account, I have attached the demo app recording above for your perusal.
Links
Here are some useful links if you are interested in checking out this project!