TL;DR
Project concerned with creating an evaluation metric for assessing originality of texts produced by AI models, human written texts or a combination of both. The pipeline follows sample data being classified in various ways as AI-written or Human-written by different detector models and combining their scores as per calculated weights to obtain insights into whether the text was truly “original”.
Motivation
The advent of Large Language Models and Neural Networks to generate human-like texts and responses has made a lasting impact on how AI will play a considerable role in automating several corporate and academic environments. Our project intends to evaluate the measure of how original a given text is and possibly classify it as AI or Human-written.
Currently, ChatGPT [OpenAI, 2022] has the best performance among the tools in the market in terms of generating coherent and persuasive answers. This is the reason it has one of the fastest growing user bases. While it can be used as a tool to assist in all kinds of work, there has been a rapid increase in its misuse. This has made it imperative to include some AI-generated results detectors to counter the growing misuse of the technology.
The primary objective of this project is to use DetectGPT, GPTZero, and OpenAI to create a model that formulates an Originality Score that is a cumulative result of the above models on the selected text datasets (obtained from a combination of human-written and ChatGPT-generated texts), thus enabling us to form better conclusions as to how similar the texts generated by the AI language model are to actual human ones.
Basically the goal is to achieve this pipeline!
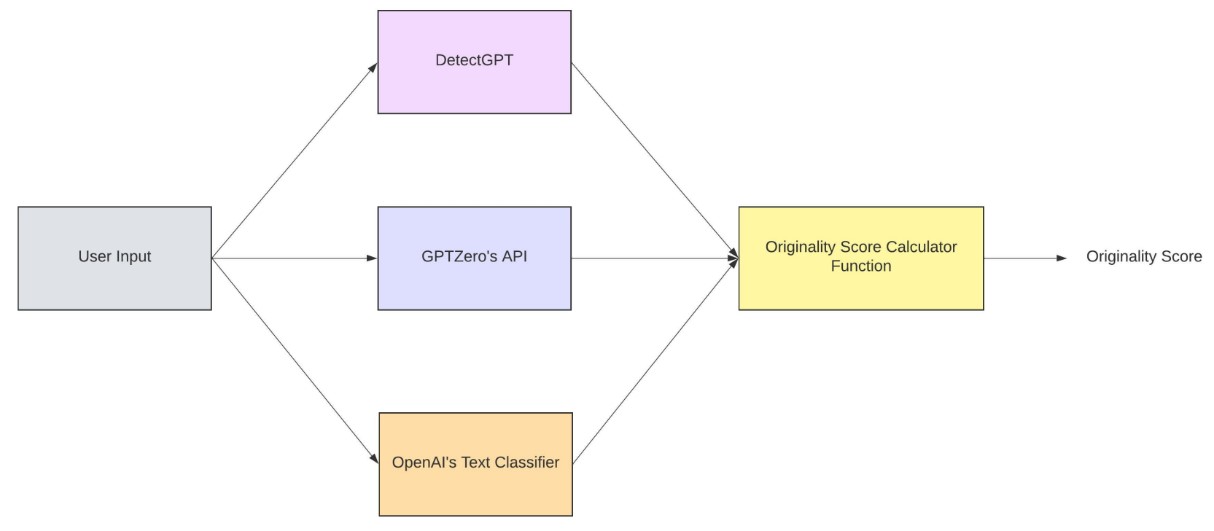
The Project
Our project centers on developing a model that can produce the originality scores of texts, including the outputs of Large Language Models (LLMs) by combining AI detector results with LLM outputs as features. We shall use various detectors, including DetectGPT, GPTZero, and OpenAI to produce verdicts and measures that contribute to a specific verdict (Human or AI generated).
The dataset used was the GPT-wiki-intro Dataset
Features extracted from the dataset were : Average Perplexity, Burstiness, Completely Generated Probability, z-score and a range of accuracy outputs from the Open AI Classifier.
The tasks defined for the project were as follows:
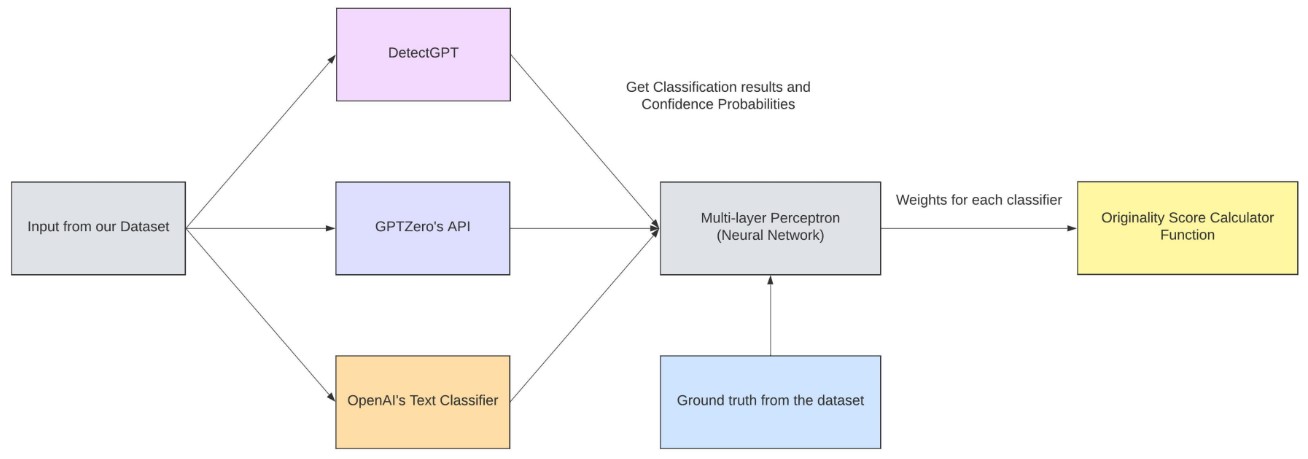
- Classification task - using a Multi-layer Perceptron model classifying data into human-generated or machine-generated.
- Weight Generation Task - to generate weights for each classifier to be learned by the model.
- Originality Score Generation - the final desired outcome, a number between 0 to 1 indicating the chance a text was generated by an AI model.
Here’s a snapshot of the Model Architecture to obtain weights!
Extension of Work
We realized there were a lot more directions we could explore with the dataset and features we had extracted, so we got to the extension part of the project which involved the following 2 experiments.
-
Supervised Learning approach : An attempt to bypass the use of all detectors by using supervised learning to create a model that directly predicts originality scores based on “text” and “originality score” features.
-
Reinforcement Learning with Human Feedback : Based on InstructGPT implementation utilizing Proximal Policy Optimization. This is a more robust model as it is impervious to incorrect signals.
Links
Here are some useful links if you are interested in checking out this project!