TL;DR
Project concerned with generating political speech coherent with the styles of renowned world leaders through Deep Learning models and Large Language models and assessing their accuracy in producing new content that keeps in line with the vocabulary, style and tone of the political figure chosen. Data science is used to create visualizations on the generated text comparing it to the original text. Here’s a funny meme from the Orange County Register that is in line with what the project tries to assess!

The Project
Employing Artificial Intelligence (AI) to be modelled after the political personalities that govern our societies may not be a distant dream after all. The aim of the project was to create a system that generates political speeches, and figured out what the topics of focus were, for each of these generated speeches.
The idea was to take a text generation model (in our case, we took GPT, BERT, RNNs, etc), train it with political speeches picked from multiple political figures, and finally prompt the model to generate a speech, given the input. These leaders have been picked considering their contributions and influence to coursing the political structure of the world.
The system was trained using a manually created dataset comprising of the most memorable and historic 5-6 speeches spoken by these political figures on a public platform. We have attempted to procure a political text generator with the highest level of consistency in the manner of speaking of these individuals.
The study encompasses dataset curation, model fine-tuning, analyses employing diverse language models, and a comprehensive evaluation using multiple metrics, such as cosine similarity, BLEU score, and ROUGE score. We now present 9 fine-tuned models (based on GPT-2 and GPT-3.5 mainly) as well as their evaluated outputs for each of the political figures we selected that perform the best, considering the resources that were openly available for our use. Notably, our research outlines potential future avenues, including topic-specific fine-tuning and deeper analyses of speech nuances.
Interesting Finds
Here is a Word-cloud representation of the most frequently used terms by each of the political figures we considered!

Here are the results of the Latent Semantic Analysis performed for Topic Modeling for each of the political figures!

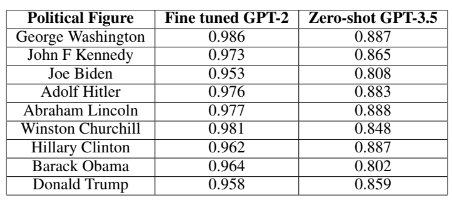
Here are the evaluation results, specifically the Cosine Similarity measure with respect to the Ground truth text. In simple terms, the closer the score is to 1.0, the better the model is at generating speech similar to the political leader!
Extension and Future Work
Political speech generation is a specific niche that can be explored to its limits. We tried our best to experiment with as many models as we could and in the process, have become well-versed with exactly which models can and cannot be used for text generation, for example, both BERT and ROBERTA do not come in handy for our purpose. We haven’t yet found a model that beats GPT in this case.
For future work, we can try building a model that can form complete and grammatically correct sentences, which are also factually correct. With the help of LDA, we can also fine-tune models to focus on particular topics only and generate text relevant to that topic. This can further be utilized to ask questions to the model and compare the text generated across various people, and analyze whose answer is most relevant to the topic.
An interesting evaluation metric that could be analyzed in the future could be reported between the models we employ for speech generation and compare performances between zero-shot learning, few-shot learning and transformer models in terms of tone of the speech, audio analysis and even video clippings. We would ideally present an in-depth analysis of the speeches of each political personality we have considered and identify the nuances which make their speech styles and formats so distinctive from one another.